東京大学大学院工学系研究科技術経営戦略学専攻松尾研究室(教授:松尾 豊、以下「松尾研」)は、この度日本語・英語の2ヶ国語に対応した100億パラメータサイズの大規模言語モデル(Large Language Model ;LLM)を事前学習と事後学習(ファインチューニング)により開発し、モデルを公開しましたのでお知らせします。今後も、Weblab-10Bのさらなる大規模化を進めるとともに、この資源を元に、LLMの産業実装に向けた研究を推進して参ります。
松尾研は、知能の謎を解くことを目的に人工知能の研究に取り組む研究室です。現在はテキスト生成で注目されることの多いLLMの技術ですが、今後は画像組み込みなどのマルチモーダル化、ブラウザ・ソフトウェア・ロボット等の行動制御の実装に発展し、人工知能研究を加速させると期待されます。また、LLMの開発競争が世界で激化する中、技術を理解した人材の育成も重要です。本研究開発は、上記の通り研究室の人工知能の研究を加速させるとともに、研究開発から得られた知見を講義開発等に生かすことで、大学における教育活動に資することも意図しています。
発表の詳細
近年の大規模言語モデルは、インターネットから収集した大量のテキストデータを学習に用いますが、そのテキストデータの多くは一部の主要言語(例えば英語)で構成されており、それ以外の言語(例えば日本語)のテキストデータを大量収集することには現状では限界があります。そこで松尾研は、日本語だけでなく英語のデータセットも学習に用いることで学習データ量を拡張し、言語間の知識転移を行うことで日本語の精度を高めることを目的とした100億パラメータサイズの大規模言語モデル“Weblab-10B”を開発し、公開しました。
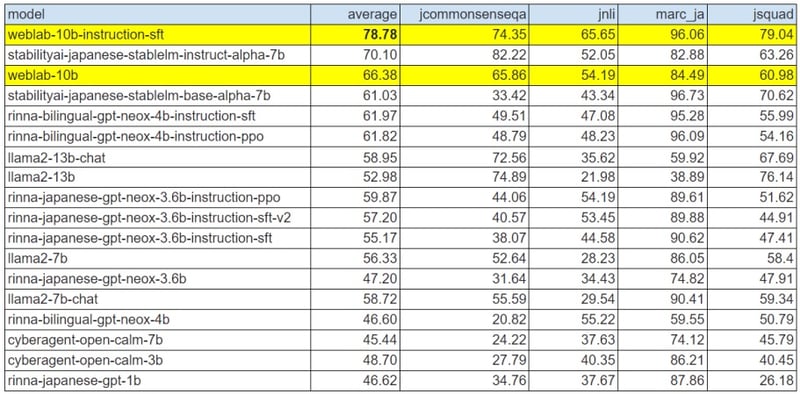
日英2ヶ国語対応の大規模言語モデル開発にあたり、事前学習には代表的な英語のデータセットThe Pileおよび日本語のデータセット Japanese-mC4を使用しました。事後学習(ファインチューニング)には、Alpaca(英語)、Alpaca(日本語訳)、Flan 2021(英語)、Flan CoT(英語)、Flan Dialog(英語)の5つのデータセットを使用しました。事後学習の日本語データ比率が低い(注2)にも関わらず、日本語のベンチマークであるJGLUE評価値が事前学習時と比べて大幅に改善(66→78%)し、言語間の知識転移を確認しました。この精度は、国内の公開モデルとしては最高水準であり(注1)、海外の公開モデルと比較してもひけをとりません(下記公開モデル比較表を参照)。
今後、世界と伍する事のできるさらに大きな日本発の大規模言語モデルの開発に挑戦します。大規模言語モデルの開発に強い意思と情熱を持っている方は以下の採用ホームページをご確認ください。
■松尾研採用ホームページ
https://weblab.t.u-tokyo.ac.jp/join-us/jobs-2/
■開発モデルの公開URL
今回開発されたWeblab-10Bの事前学習済みモデル・事後学習済みモデルは、商用利用不可のモデルとして公開します。(下記Hugging Faceのページを参照)今後、商用利用可のモデル開発も検討していきます。
・事前学習済みモデル
https://huggingface.co/matsuo-lab/weblab-10b
・事後学習(ファインチューニング)済みモデル
https://huggingface.co/matsuo-lab/weblab-10b-instruction-sft
■公開モデル比較表(注1, 注3)
■生成サンプル文

■モデル名“Weblab-10B”の由来
Web工学の研究から始まった松尾研が、研究室立ち上げ当初から長く使用し、メンバーからも親しまれているドメイン名を利用しました。Webという言葉には「蜘蛛の巣状の」という意味もあります。さまざまな人が交錯しながら価値を生み出していく松尾研のあり方にも重なるものでもあり、今回開発した100億パラメータ(10 Billion)のLLMが、新たな研究との結節点となることを期待しています。
今後も松尾研は大規模言語モデルの研究・開発を切り口に、人工知能技術の社会実装、大学における実践的な教育活動に取り組んでまいります。
注釈
(注1)JGLUE評価での実績(2023年8月16日時点)
JCommonsenseQA-1.1、JNLI-1.1、MARC-ja-1.1、JSQuAD-1.1の平均値を使用。本モデルにおける評価は、Stability-AI/lm-evaluation-harnessライブラリを用いて、float16でモデルロードを行い、template version 0.3でfew-shot in-context learningによる評価を実施した(few-shot数は3,3,3,2)。
(注2)事後学習には、以下のデータセットを使用:Alpaca(英語)、Alpaca(日本語訳)、Flan 2021(英語)、Flan CoT(英語)、Flan Dialog(英語)。JGLUEタスクに類似したクラス分類/文章読解を含むデータセットはFlan 2021(英語)だが、日本語訳が含まれていないにも関わらずパフォーマンスが改善した。
(注3)本モデル以外の評価結果は、Stability-AI/lm-evaluation-harnessから直接引用(2023年8月16日時点)
https://github.com/Stability-AI/lm-evaluation-harness/tree/2f1583c0735eacdfdfa5b7d656074b69577b6774
※このたびOSI(Open Source Initiative )の定義に倣い、Weblab-10Bについては商用利用不可のため“オープンソース“の定義に当てはまらないものとして、2023年8月18日発出のリリースの一部文言を訂正しました。
プレスリリース本文(2023年8月22日訂正版):PDFファイル
東京大学松尾・岩澤研究室 GENIACプロジェクトにおいて、大規模言語モデル「Tanuki-8×8B」を開発・公開

大規模言語モデルを用いた有機分子設計手法の開発 ―AIと対話して分子を設計―
