Authors
Zhongyi Zhou, Koji Yatani
Abstract
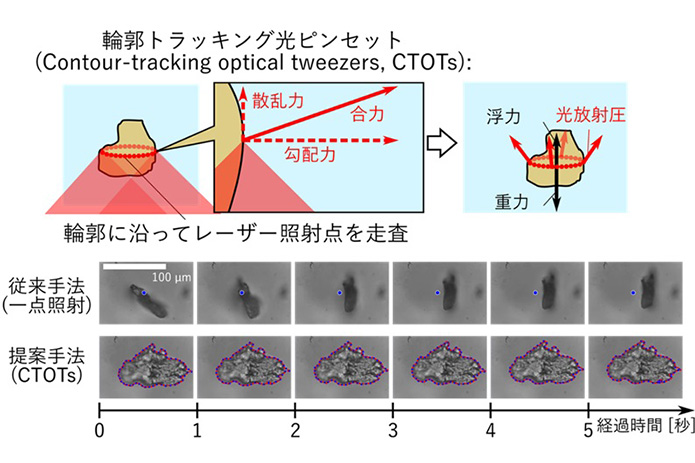
Interactive Machine Teaching (IMT) systems allow non-experts to easily create Machine Learning (ML) models. However, existing vision-based IMT systems either ignore annotations on the objects of interest or require users to annotate in a post-hoc manner. Without the annotations on objects, the model may misinterpret the objects using unrelated features. Post-hoc annotations cause additional workload, which diminishes the usability of the overall model building process. In this paper, we develop LookHere, which integrates in-situ object annotations into vision-based IMT. LookHere exploits users’ deictic gestures to segment the objects of interest in real time. This segmentation information can be additionally used for training. To achieve the reliable performance of this object segmentation, we utilize our custom dataset called HuTics, including 2040 front-facing images of deictic gestures toward various objects by 170 people. The quantitative results of our user study showed that participants were 16.3 times faster in creating a model with our system compared to a standard IMT system with a post-hoc annotation process while demonstrating comparable accuracies. Additionally, models created by our system showed a significant accuracy improvement (ΔmIoU = 0.466) in segmenting the objects of interest compared to those without annotations.

ACM Digital Library: https://dl.acm.org/doi/10.1145/3526113.3545648
Dynamic transition and Galilean relativity of current-driven skyrmions
Topological magneto-optical effect from skyrmion lattice